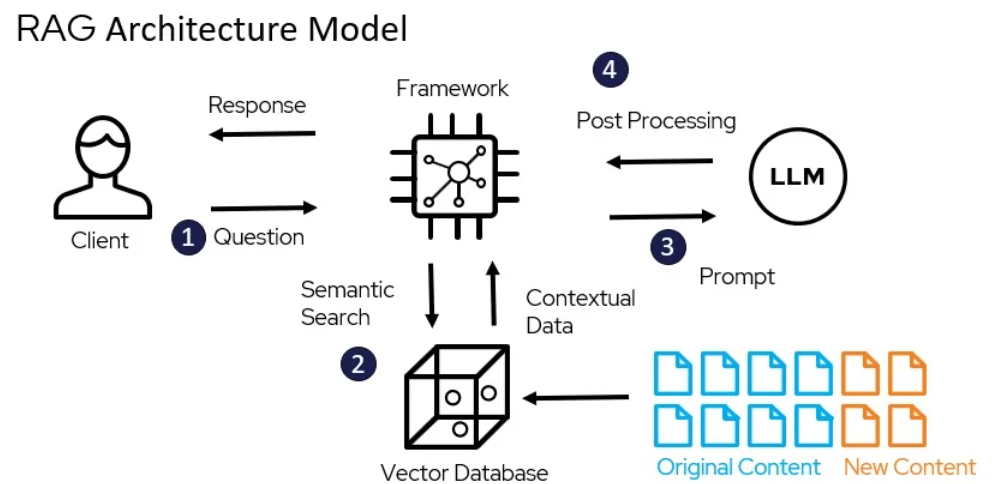
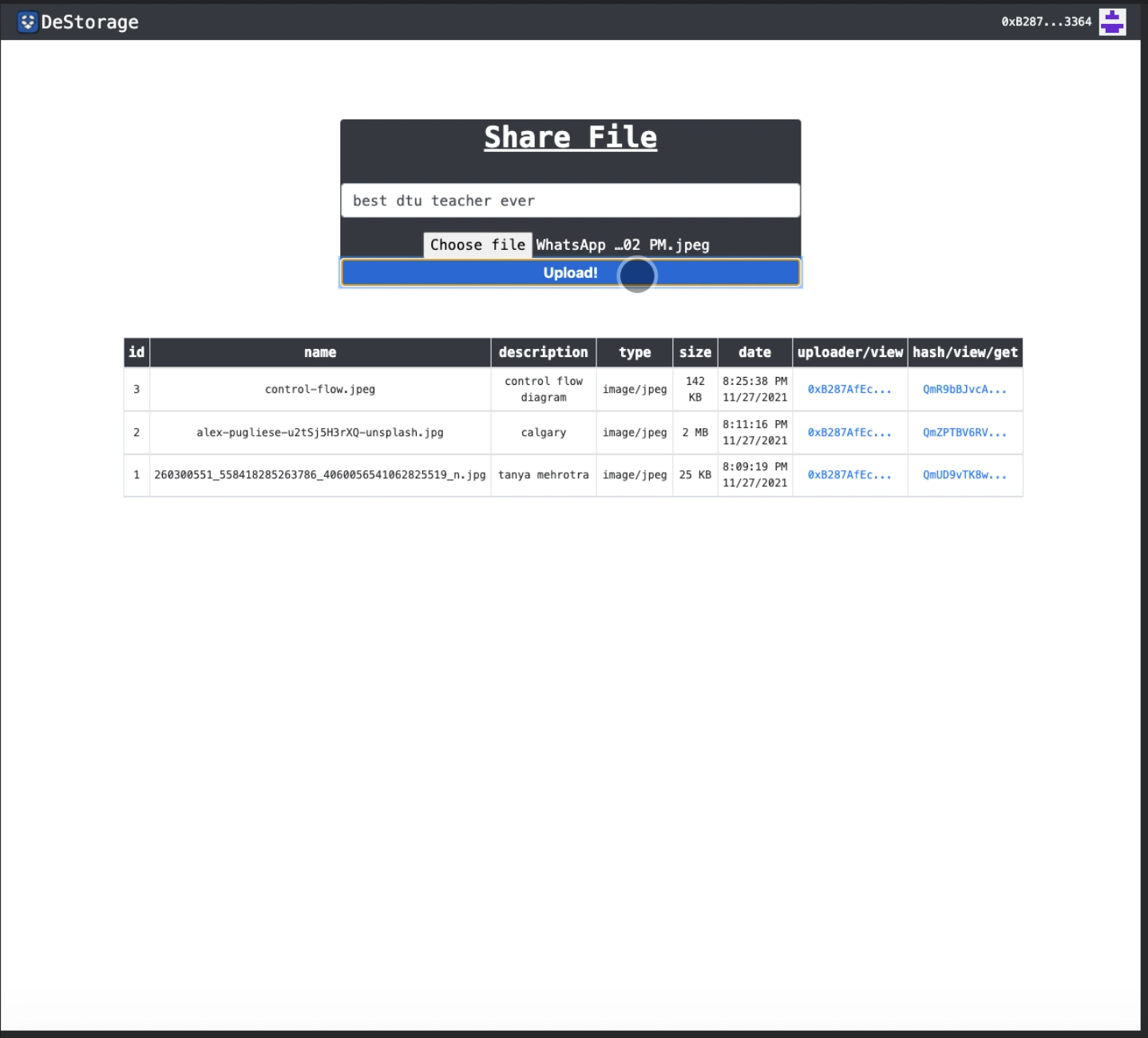
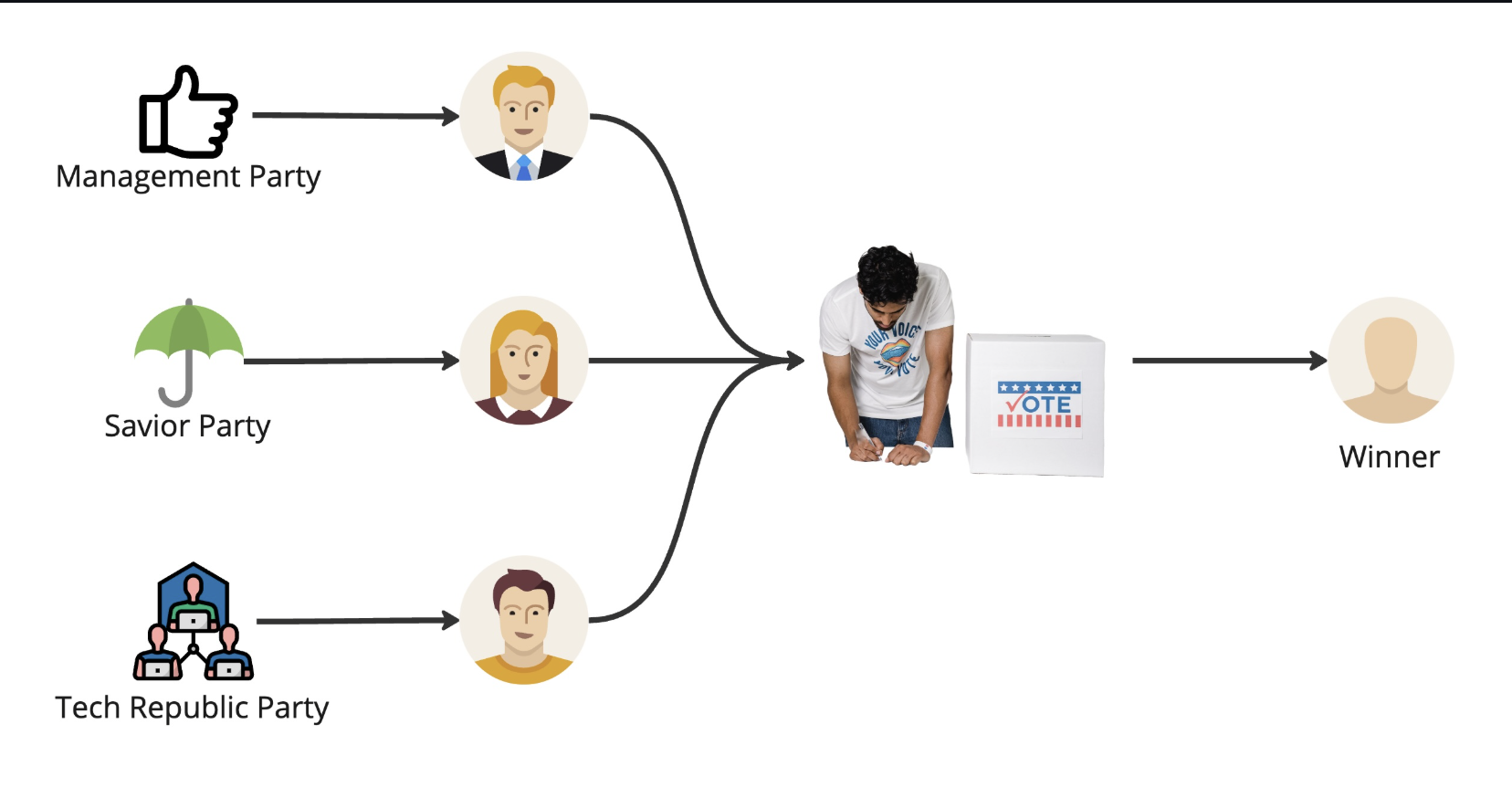
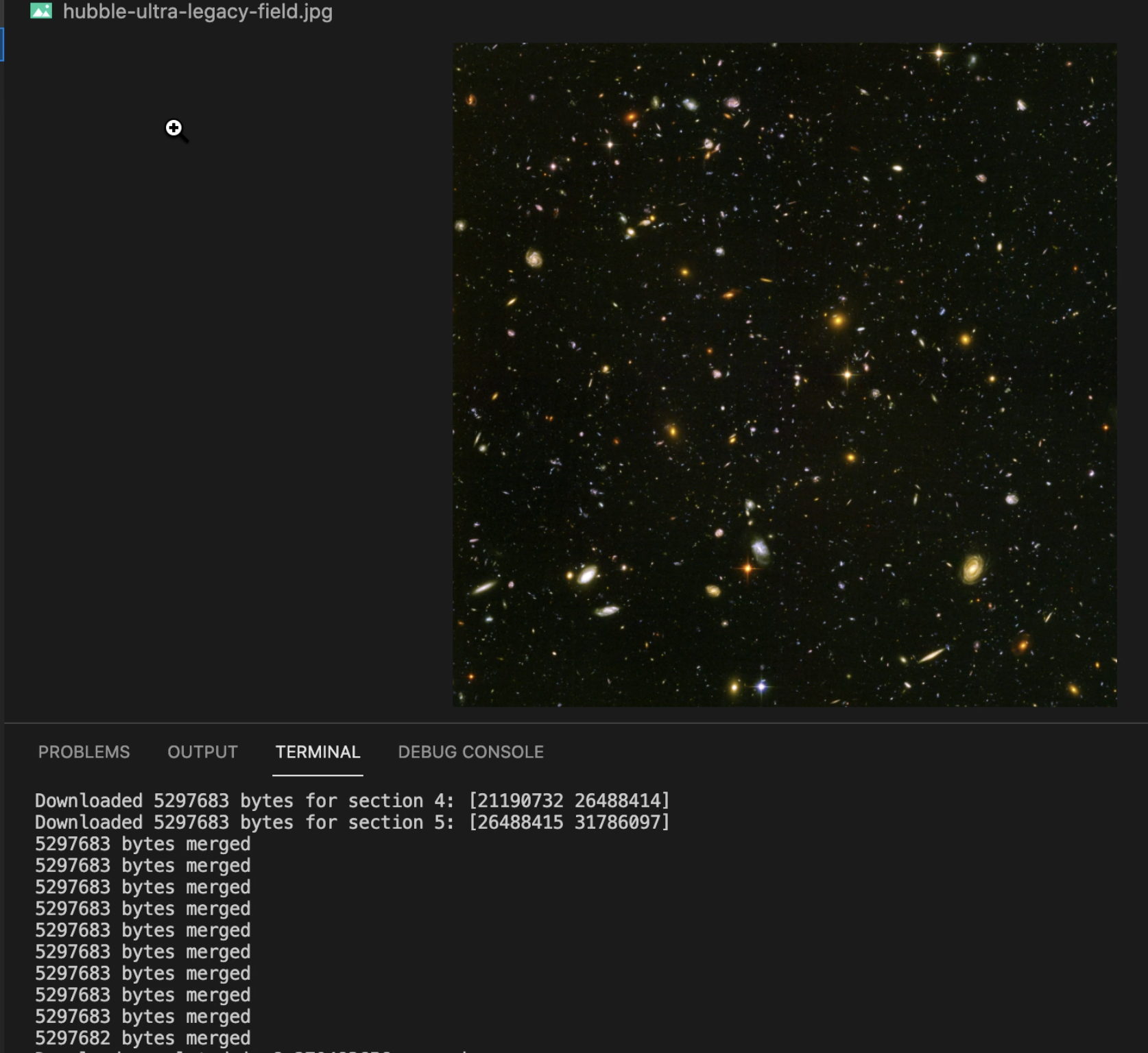
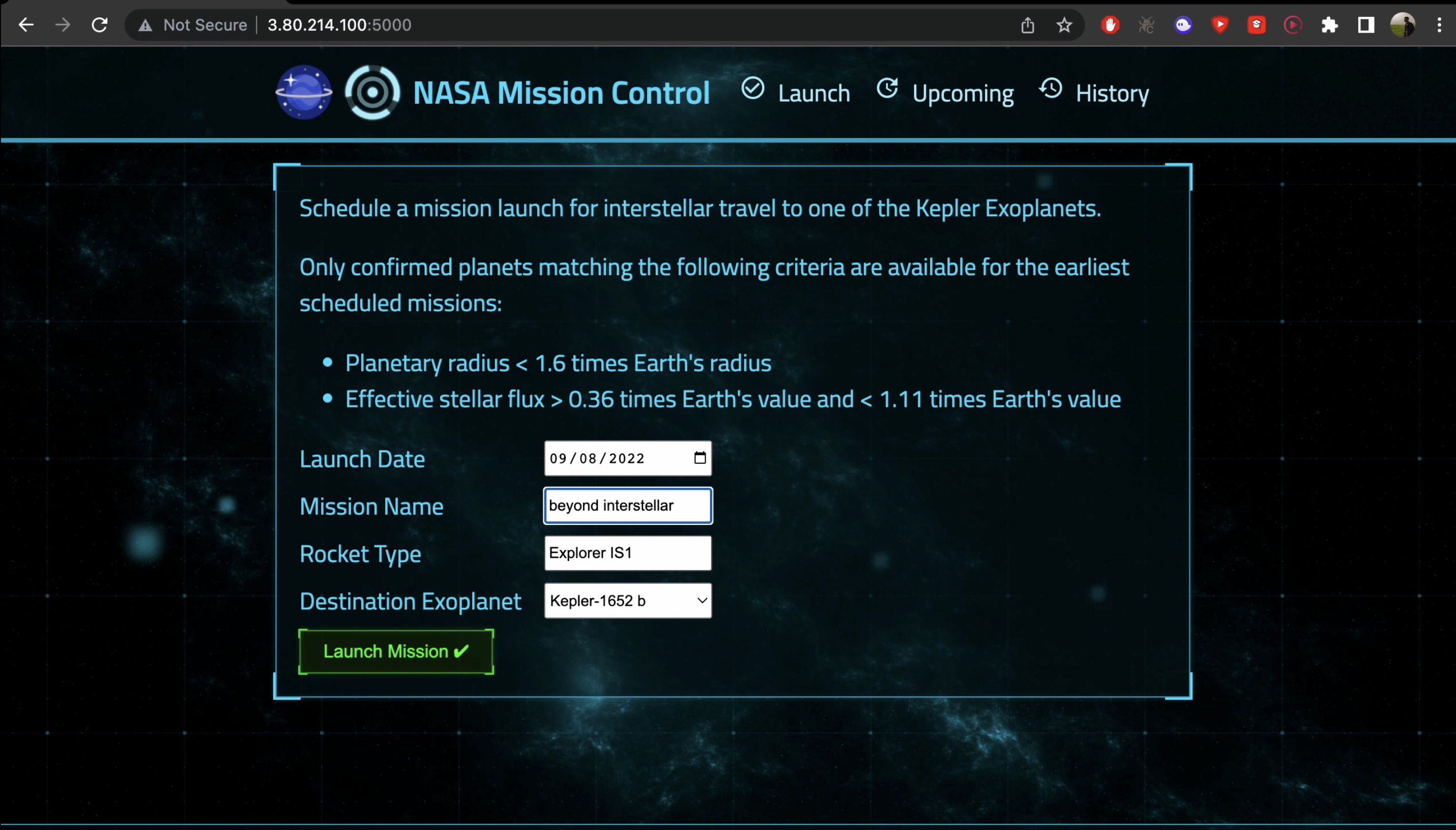
About
Hi 👋🏻, I'm Warid
I'm a Full Stack Software Engineer with a background in AI & DevOps Engineering.
Being an open-source software fanatic, I have contributed to several projects, both voluntarily and through funded programs such as Google Summer of Code, Linux Mentorship, and Summer of Bitcoin. You can find these contributions below: